Datathons: fostering equitability in data reuse in ecology
Why a Datathon?
Amid the global biodiversity crisis, there's a growing need to collect, organize, and share biodiversity data worldwide. Historically, local funding has shaped data practices, leading to knowledge gaps in the state of biodiversity. To address this, improving data archiving practices is a cost-effective first step to enhance global microbiome data coverage. Regions with limited resources can reuse data for fresh insights, especially in expensive sequence-based biodiversity research. Data reuse in microbiome research enables researchers to produce high-quality work, including those with limited access to resources or funding.,Promoting data reuse can incentivize archiving, increasing the quantity and quality of reusable microbiome data, particularly in countries with limited research funding. As global synthetic microbiome research grows, diverse perspectives foster innovation and understanding of microbiome ecosystems.,The Datathon brings researchers in microbial ecology together to archive and reuse local metabarcoding sequences, enhancing discoverability and reusability of regional microbial data. It gives data producers academic credit for their work and creates a valuable resource to foster biodiversity research blind spots. Crucially, the Datathon aims to stimulate synthesis research by participants using the deposited sequences.
Datathon's phases
The Datathon is organized over the course of three days in a hybrid format, each day with a distinct focus.,Day one (Inspire) features a hybrid symposium delving into the history of synthetic research in ecology, the relevance of 'Open Data' in biodiversity research, and the potential and outcomes of recent global biodiversity data syntheses.,Day two (Support) focuses on remote, hands-on data deposition in NCBI's Sequence Read Archives, aided by custom online guides in English and Spanish. These guides include a custom metadata sheet with specific fields to allow the rapid integration of all datasets and facilitate post-Datathon data reanalysis. In addition to standard NCBI metadata fields, fields for technical information and the DOI of publications related to the data are included. Additionally, a three-level ontology improves sample environment descriptions. This day, participants can access a dedicated Slack helpdesk channel for personalized assistance, ultimately enhancing the quality of data deposition.,Day three (Collaborate) focuses on combining participants' deposited data for its reuse and developing collaborative networks. Participants create Slack channels to brainstorm research ideas and select leaders for synthesis projects. After the event, participants receive detailed summaries of the data resources and projects and can choose to participate.
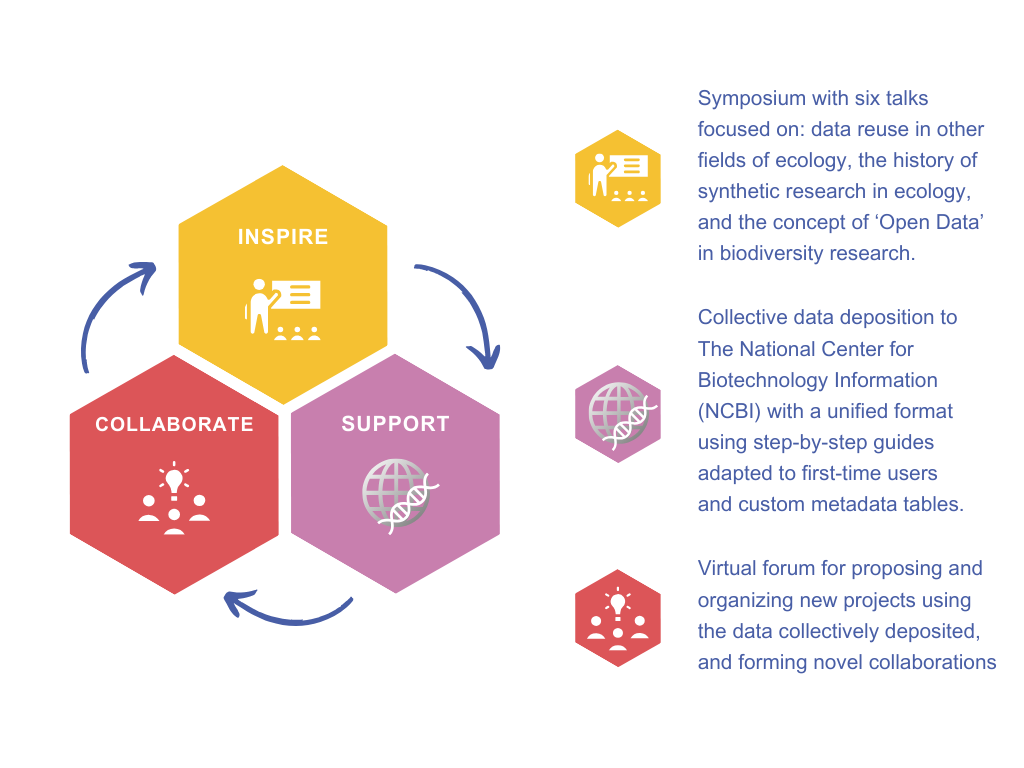
Datathon's Phases
See our first Datathon articles here and here.
Find out more about our ongoing projects: